Empowering data mesh: The tools to deliver BI excellence

The data mesh framework
In the dynamic landscape of data management, the search for agility, scalability, and efficiency has led organizations to explore new, innovative approaches. One such innovation gaining traction is the data mesh framework. The data mesh approach distributes data ownership and decentralizes data architecture, paving the way for enhanced agility and scalability.
With distributed ownership there is a need for effective governance to ensure the success of any data initiative. In this blog, we’ll delve into the critical role of governance and data modeling tools in supporting a seamless data mesh implementation and explore how erwin tools can be used in that role.
erwin® by Quest is well-known for its data modeling tool, erwin® Data Modeler by Quest, used to draw data models and engineer database schemas across the enterprise. erwin also provides data governance, metadata management and data lineage software called erwin Data Intelligence by Quest. This software offers a host of data governance functionality, including metadata management, business glossaries, data lineage, data exploration, data quality management, data marketplace, and code generation for data pipeline automation. With erwin Data Modeler and erwin Data Intelligence working together, teams can experience powerful support for the needs of data mesh governance.
Decentralized data, centralized governance
Data mesh breaks monolithic data architectures into smaller, more manageable decentralized domains. This empowers individual teams to own and manage their data. Decentralization has a downside, a risk of anarchy. To avoid this, we need to implement a robust governance framework.
Governance and automation tools, such as erwin, have features that can support a centralized governance team to monitor, control, and ensure the quality, privacy, and compliance of distributed data across domains.
Governance is difficult. It requires discipline, and information in the form of metadata about those being governed so that remedial action can be taken to hold people to account and ensure policies are being followed.
We see the following topics as important steps towards delivering a working business governance system:
- Metadata Management – managing the data we need to perform data governance
- Separation of Data – allowing working in a decentralized way
- Data Quality – is the data suitable for its intended business use?
- Business Glossaries – what is the business meaning of our data?
- Data Marketplace – how is data consumption democratized?
Metadata management
The data mesh governance function needs to have basic information about data used by the organization.
This includes data at rest, details of databases, schemas, tables and views. It also needs to know about the flow of data; how it flows from one system to another and any transformations that may occur when it flows. It needs to know how these change over time.
Gathering this data isn’t possible without automation. erwin Data Intelligence has the functionality to scan the organization’s data estate and capture metadata about all data held in databases. It can also drill down inside SQL statements, scripts and a whole host of ETL tools to identify and capture data about data transformations, building a picture of data lineage. What’s more is that erwin Data Intelligence allows you to scan the organization repeatedly and to version control the resulting data, allowing you to identify and monitor changes in the data estate.
We would suggest that you configure erwin Data Intelligence to scan the enterprise every week to capture metadata and that you ensure you have a choice of smart data connectors that can interrogate your specific ETL tools to produce the lineage.
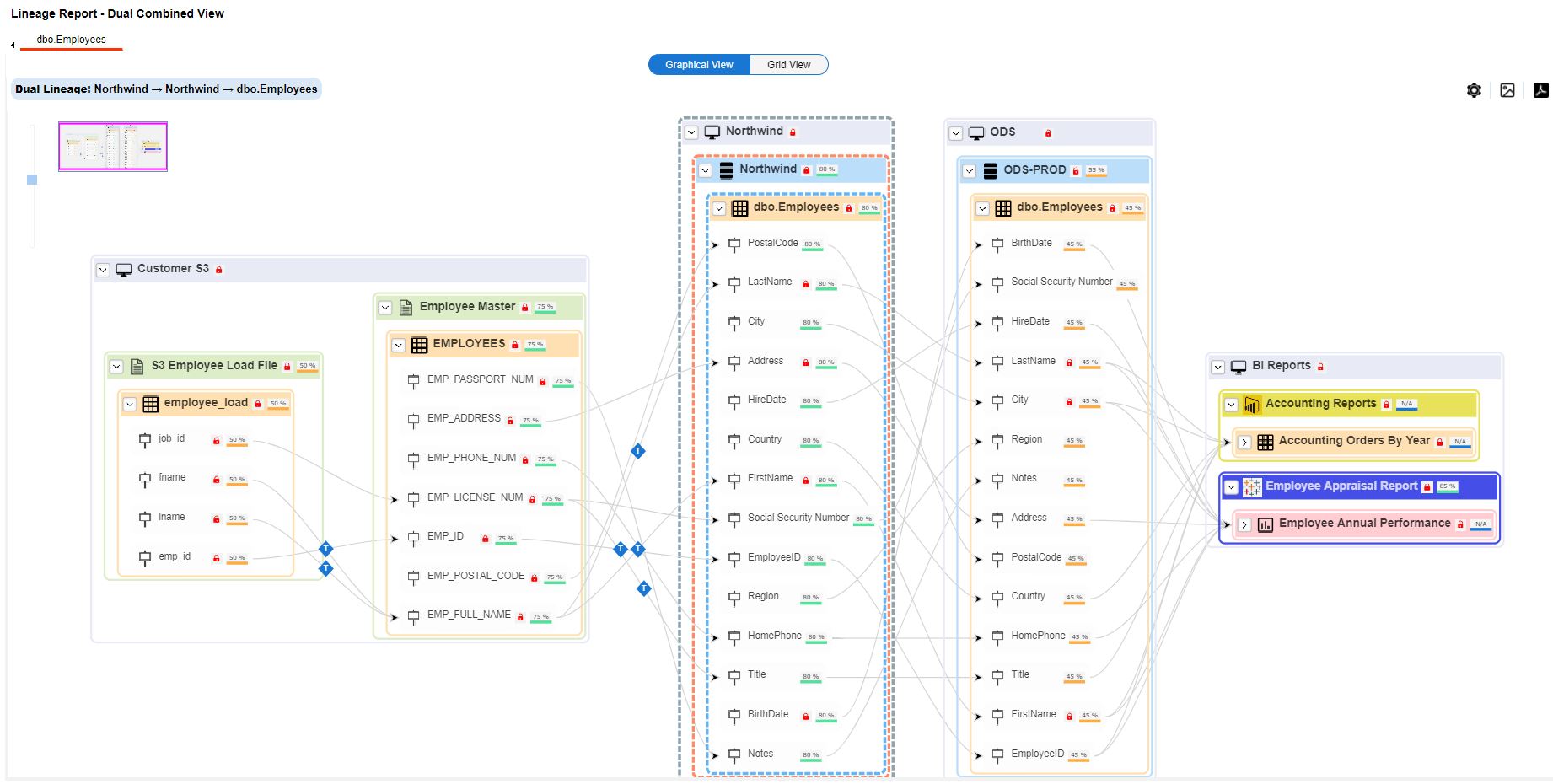
While the base metadata is useful, and you can display lineage diagrams showing the flow of data tables or individual columns across the business, the data needs to be attributed to various teams, and linked to glossaries and policies to support governance control and analysis.
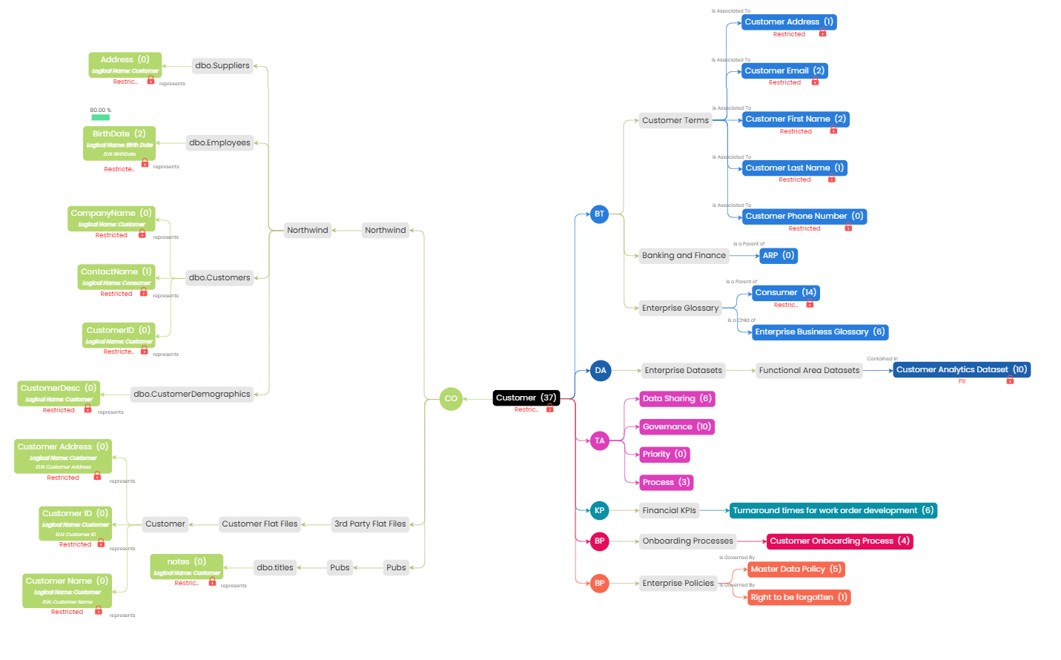
Separation of data
Data mesh encourages distributed data ownership. It allows data teams to work with the data inside their own local domain, only imposing standards on data when a data product is exposed for use by other domains.
This means that domain teams need to have their own walled garden to work with data inside their domain, where no other domain can see or access that data. They must also have a public-facing area where they can expose data products for any other domain to access and use.
erwin Data Modeler can use new project areas for each domain to model their data. We’d suggest setting up one project for internal data sets, perhaps one per source system if the domain is supported by more than one application, as well as one for integration of internal analytical data. A further project can be used for externally facing data products. Likewise, for erwin Data Intelligence, data sets can be organized into domains, with each domain having a metadata subset for each source system, one subset for the internally focused integrated analytical data set, and one for the external data products.
erwin Data Intelligence uses access to source systems to collect metadata. To load metadata about the internally focused integrated analytical data and data products, the data engineer should model them using erwin Data Modeler and then import metadata into erwin Data Intelligence.
Data quality
One of the earliest tasks of data governance is to get control over and improve the level of data quality across the organization. The garbage in, garbage out rule applies to the data mesh architecture as much as other IT areas.
Data quality improvement isn’t rocket-science. It does require a process, buy-in and the application of energy.
The basic process is:
- Find information about the data we have (done in the metadata step above)
- Categorize data in a proper way (usually by business capability, e.g. HR data, Finance data)
- Assign data stewards responsible for the data in certain capabilities, e.g. who manages work on the finance data set?
- Discover data quality measures and business rules for organizational data
- Prioritize efforts, and work through the data systematically over time
- Implement a data quality check as a data query (for example primary keys are unique, certain columns are mandatory or should be 90% completed, foreign keys reference real data)
- Run the data quality check over the data. Measure compliance and find instances where the rule is broken
- Notify the data steward of the data items that break the quality rules
- Hopefully, they can fix the data at source, but also take steps to stop the errors happening in the first place through policies, process changes, checklists, training, or other interventions
- The data quality monitoring should see an improvement in the number of records failing the quality check
- As the data quality improves, then move onto the next data quality rule
- Continue onwards, adding more sophisticated rules over time, gradually improving the baseline quality of the data
erwin Data Intelligence in hand with its integrated data quality offering, erwin Data Quality, has functionality to support coding of data quality checks, to check data held across the organization, and to make data stewards aware of the data items that need to be corrected. This will involve setting up a network of data stewards, connecting them to domains and onward to the data within those domains, creating rules associated with data objects, and running the rules on a regular basis. With access rights, data stewards can be restricted to access just the data sets within their scope of responsibility.
Business glossaries
A business glossary is a dictionary, a set of definitions of common business terms or concepts used within the business. The definitions of glossary terms are unique to each new enterprise yet have much in common.
The data mesh governance team has the choice of allowing different glossaries to exist within each domain, as well as having a centralized glossary; or having just the one glossary. We prefer the latter, as it helps with later integration work.
We suggest that concept models are produced using erwin Data Modeler. These name the things of importance to the enterprise (noun concepts) and relationships between them (verb concepts). These can be shared from erwin Data Modeler into erwin Data Intelligence’s business glossary management area.
Glossary management involves two types of work – defining the terms, which involves drafting definitions and taking them through various committees to refine and sign off on the definitions and linking the glossary terms to the actual data held in the enterprise (which we have already collected using the metadata management functionality of erwin Data Intelligence).
Linking data items to terms is fairly easy to do and is supported by AIMatch functionality that suggests matching data to terms, giving the data engineers a boost to their productivity and accuracy/consistency of work. The linkage needs to be kept up to date as the organization’s data evolves, and the erwin versioning of the collected metadata helps find changes from version to version that need to be addressed. We let each domain team link their data, with some governance input to perform QA, and to find items that are yet to be linked to chase up.
Defining terms is a longer process. We tend to record working definitions as a starter for the process to allow technical work to go ahead, while waiting for the committees to catch up. We find that a small number of the terms are crucial for the business and that these take the most time to agree. Many terms are relatively uncontroversial, and it is easy to get consensus as to their definitions.
Data marketplace
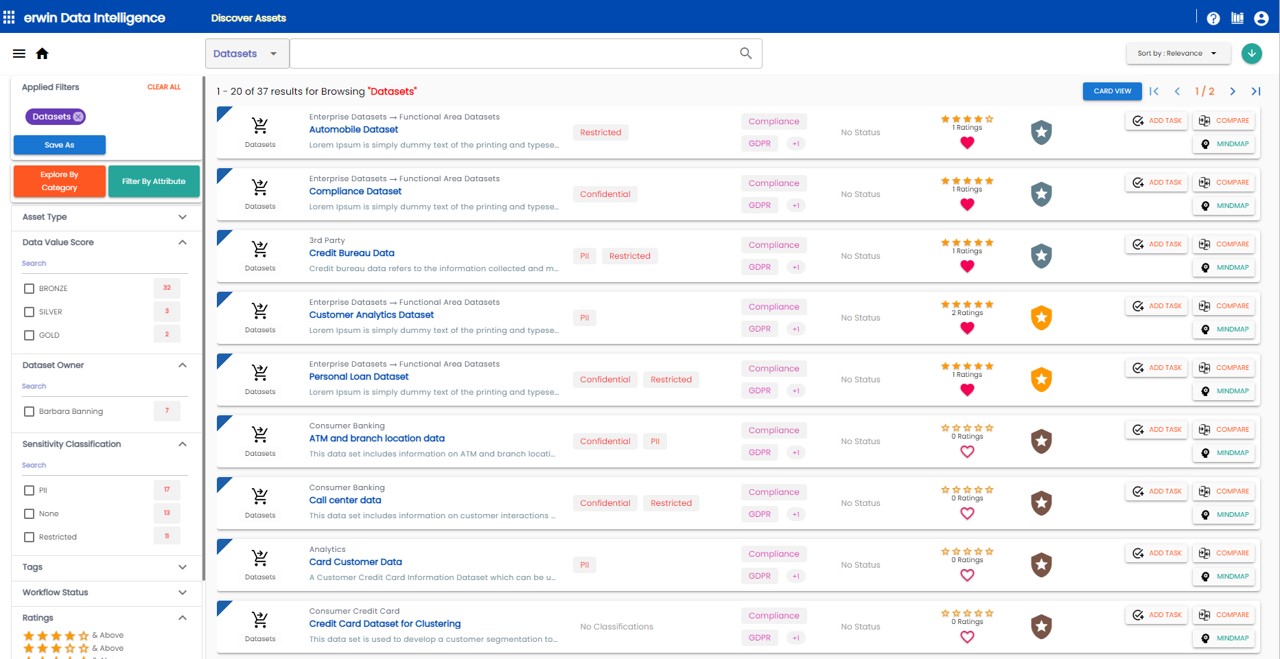
Data is only valuable when it is used. But as the number of data products grows, each offered by different domain teams, so it becomes difficult for those who want to access data to be able to find it.
Data mesh suggests setting up a central register of data products and has a search feature or functionality to allow users to search for, identify and make use of existing data products.
The erwin Data Marketplace within erwin Data Intelligence allows domain teams to publish their data products and for end users to search through the data product sets to find what they are looking for. The functionality allows each product to be described, for the capture of metadata about the product (such as owner, purpose, content, domain) and for end-users to star rate the product in terms of its ease of use. It also provides organizations with a way to produce automated data value scores based on user-defined weighting of data quality scores, user ratings and governance completeness.
The Conclusion
As enterprises adopt distributed ownership approaches, data governance is key and while people and process are vital so is providing the right tools for implementation. This blog highlights how erwin Data Intelligence and erwin Data Modeler can help support a successful data mesh initiative.
About the Authors
This blog was guest authored by Neil Strange, CEO of Datavault and Richard Adams, Solution Strategist, erwin by Quest.
Neil Strange is the founder and CEO of Datavault, a leading provider of innovative data management and analytics solutions. He has over 30-years of experience in consulting, driving strategic initiatives to help businesses unlock the full potential of their data in many sectors including commercial and public sector clients. Neil has a keen understanding of the evolving data landscape, and is globally recognized as a leading expert on application of the Data Vault method.
Datavault, established in 2003, is a boutique data consultancy providing clients with data platform, governance and analytics solutions. We are passionate about using technology to solve real-world business problems. By aligning our efforts with our clients’ business goals, we help them achieve tangible results and drive success quickly and effectively.
