Data Modeling 101: OLTP data modeling, design, and normalization for the cloud

How to create a solid foundation for data modeling of OLTP systems
As you undertake a cloud database migration, a best practice is to perform data modeling as the foundation for well-designed OLTP databases. For standard relational database applications, data modeling that incorporates accepted design paradigms, such as normalization, is essential. This makes mastering basic data modeling techniques and avoiding common pitfalls imperative. This blog outlines a solid foundation for data modeling of online transaction processing (OLTP) systems as they move to the cloud. Other types of databases will be covered in subsequent blogs.

Data modeling is a serious scientific method with many rules and best practices. However, the diagram is merely the starting point for an effective and efficient database design. One must also capture the vast quantity of metadata around the OLTP business requirements that must be reflected. I’m not proposing that business logic be held in the database, but it needs to be documented in the data model even if it will be implemented in application code. No matter where you implement it, you must fully document the business requirements in order to produce an effective final result.
Data modeling helps you right-size cloud migrations for cost savings
The cloud offers infinitely scalable resources – but, at a cost. When you make poor database design choices for OLTP applications deployed to the cloud, your company will pay every month for the resulting inefficiencies. Static overprovisioning or dynamic scaling will run up monthly cloud costs very quickly on a bad design. So you really should get familiar with your cloud provider’s sizing versus cost calculator.
Look at Figure 1 below. I was pricing a data warehousing project with just 4 TB of data – small by today’s standards. I chose “OnDemand” for up to 64 virtual CPUs and 448 GB of memory, since this data warehouse wanted to leverage in-memory processing. So that’s $136,000 per year just to run this one data warehouse in the cloud. If I can cut down on the CPU and memory needs, I can cut this cost significantly. I do not want to overprovision to be safe; I want to right-size this from day one based upon a database structure that does not waste resources due to inefficient design.
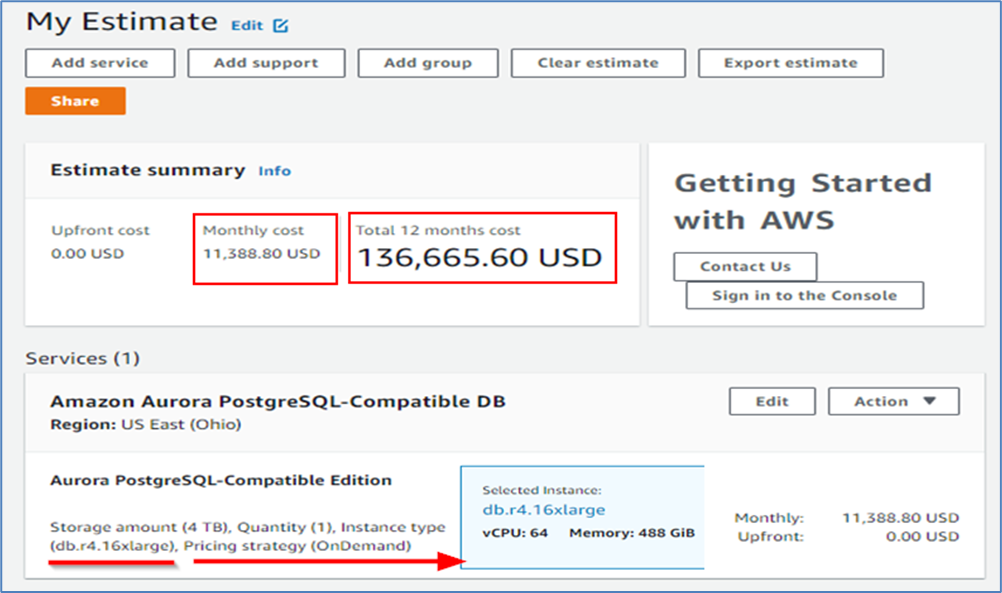
Figure 1: Amazon Cloud cost calculator
Data modeling basics
Now to cover some data modeling basics that apply no matter whether your OLTP database is on premises or in the cloud.
Step #1: Model the business requirements first, not the database or application-specific things. Don’t get hung up on physical database terms like primary keys, foreign keys, indexes, tables, etc., because you might not employ a relational database. In fact, many current development efforts are opting for the newer, NoSQL databases (which I’ll cover in a subsequent blog, but are shown below in Figure 2 for context). For example, the NoSQL database MongoDB has documents and collections instead of tables and columns. So those database terms are worthless until you know what you’re trying to do. You can decide later how you’re actually going to do it.
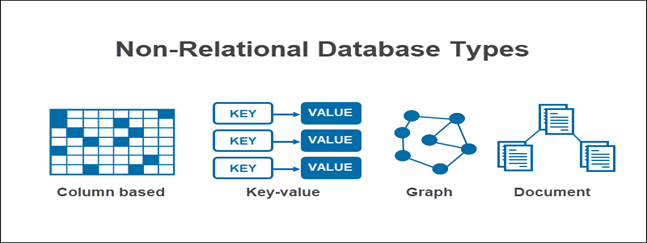
Figure 2: Popular NoSQL database types
Step #2: Model the business entities as the logical way the business naturally sees things, then later adjust the resulting physical model based upon the database type chosen. Remember, in this first blog we’re focused on traditional, OLTP-type relational databases.
What is an entity? While talking to the business people about the business requirements, entities tend to be the plural nouns that they mention: insureds, beneficiaries, policies, terms, etc. Some basic entity aspects and advice include:
- Generally, pretty easy to identify
- Just write them down, fill in details later
- Don’t mash things together, list them all at first
- Then begin to identify each entity’s attributes
One of the easiest ways to identify entities is to talk to business users, and diagram their sentences. In Figure 3 below, once we diagram the sentence, notice that there four nouns, and therefore there are four entities.
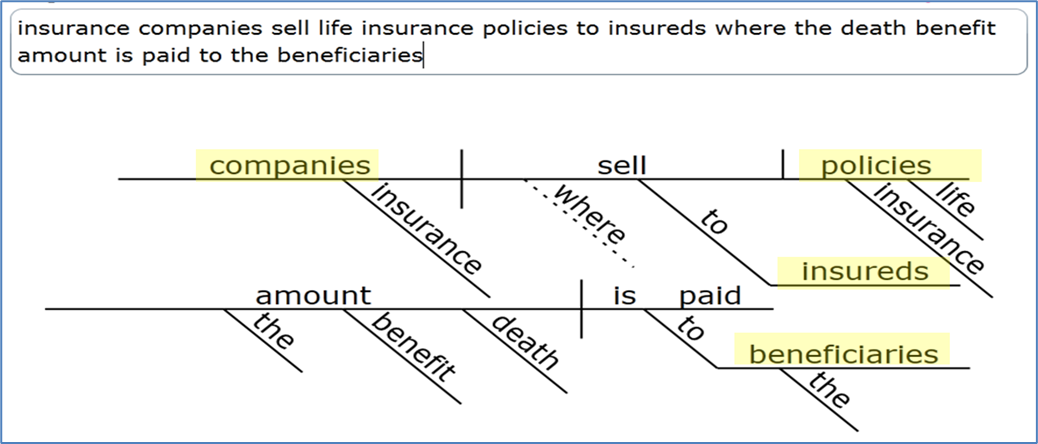
Figure 3: Example sentence diagram
Now that we have identified some entities, we need to use a data modeling tool like erwin® Data Modeler by Quest® to record this information as shown in Figure 4 below.
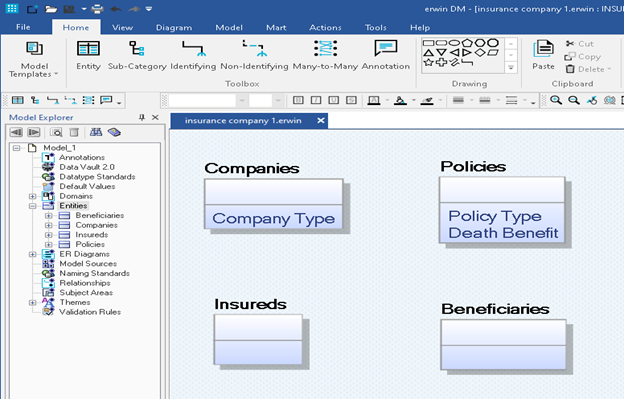
Figure 4: Entities represented in erwin Data Modeler
Step #3: Model the business attributes as the logical way the business naturally sees things, then later adjust the resulting physical model based upon the database type chosen.
What is an attribute? Again, while talking about business requirements, the attributes tend to be the descriptive nouns and adjectives that people mention. Some basic attribute aspects and advice include:
- Also, pretty easy to identify
- Define properties or characteristics of entities
- For now, don’t worry if entity has lots of attributes
- Inquire what attribute(s) produce entity uniqueness
Referring back to the sentence diagram in Figure 3, and based upon asking the business users deeper questions, we now end up adding to the diagram from Figure 4 to create the model shown in Figure 5. Note that it’s better to add any attributes possible while also realizing there may be some attributes which might not yet fit into an identified entity – so create one.
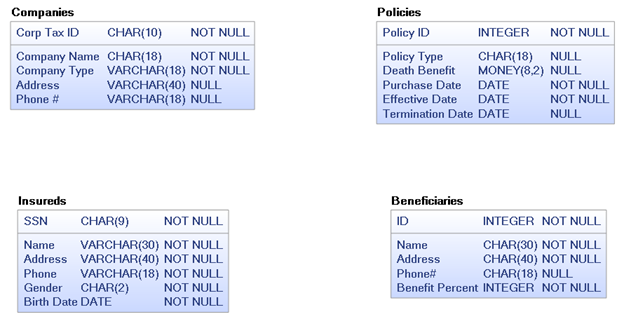
Figure 5: Adding attributes to diagram
Step #4: Model the relationships between the entities. Remember; don’t get caught up in how you think the database will implement these relationships, just document the natural ones the business identifies. After adding the relationships to Figure 5, we end up with Figure 6 below. Note that we now have some many-to-many relationships, which we know cannot be implemented in a relational database. Do not try to solve this right now. Just get all the base relationships identified; we’ll resolve any issues in the next step.
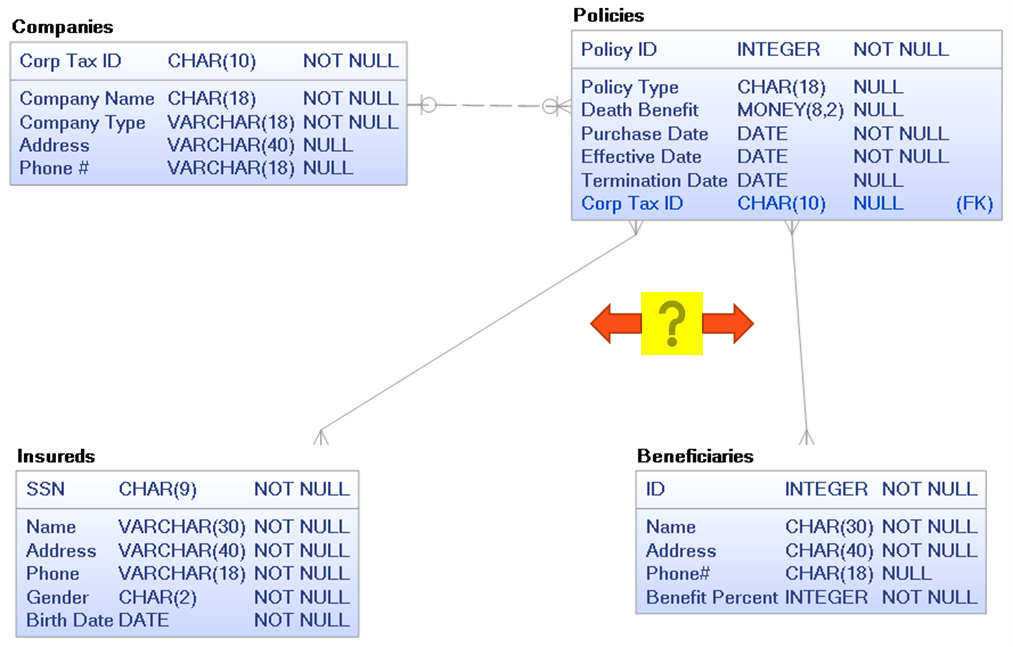
Figure 6: Identify the relationships
Step #5: Resolve many-to-many relationships via bridging or intersection entities. Not because they cannot be resolved in a relational database, but because there are very likely as-of-yet-unidentified attributes that might be housed within those new entities. In fact, I’d suggest that many, if not most, critical OLTP attributes will end up in these bridging or intersection entities. Note that many data modeling tools, like erwin Data Modeler, will offer a utility or tool to assist with this effort.
In Figure 7 below, we see two new entities were added in order to resolve the two many-to-many relationships. In this case we did not identify any missing attributes within those new entities. But there usually are, so maybe we need to ask the business users more questions. For example, do the beneficiaries have an assigned percentage of the death benefit that they receive, or is it just one Nth based on the number of beneficiaries?
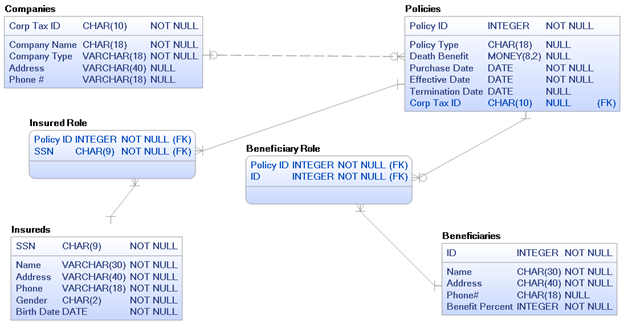
Figure 7: Bridging or intersection entities
Step #6: Identify possible super- and subtypes. Look again at Figure 7, what is the difference between an insured and a beneficiary? Aren’t they just both people? What if a person is an insured on one policy and a beneficiary on several other policies? In that case we would have to somehow propagate any address or phone number changes throughout all tuples (i.e., rows) in these entities. This data duplication can lead to inaccurate data, which no business wants. We can instead modify our model, as shown below in Figure 8, by creating a super-type (person) with subtypes (insureds and beneficiaries). We place the common attributes in the super-type, and the non-common attributes in the subtypes.
Note that you may hear the super- and subtype concept called by other names, such as inheritance hierarchies or entity inheritance. We now have solved the duplicate data problem via a better design. However, we still have a problem – that the person entity has no unique identifier and our subtypes each have one of their own. This is not desirable. In this example, this is true (and solved in next step). But in many cases the unique ID might have been common and thus moved up into the super-type.
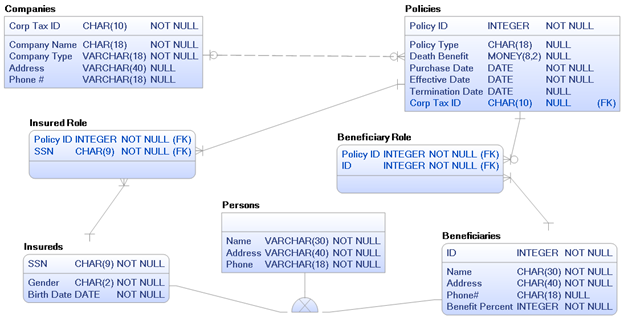
Figure 8: Create entity super- and subtypes
Step 7#: Resolve questionable unique identifiers in super- and subtypes. If you have super-types with no unique identifier, then you’ll need to find or create one. Talk to the business people and base your fix upon business ideals – not on a specific database platform or what the application developers prefer. Look at Figure 9 below. I’ve moved the ID and SSN from the subtypes up into the super-type. Moreover, after talking to the business users, they say that a unique ID would make a better unique identifier because they don’t always have a SSN. So I’ve made SSN optional and ID is the sole unique identifier. Note that the subtypes inherit the unique identifier from the super-type, so ID shows up in each super-type. Take your time on this step, it can sometimes be a little tricky.
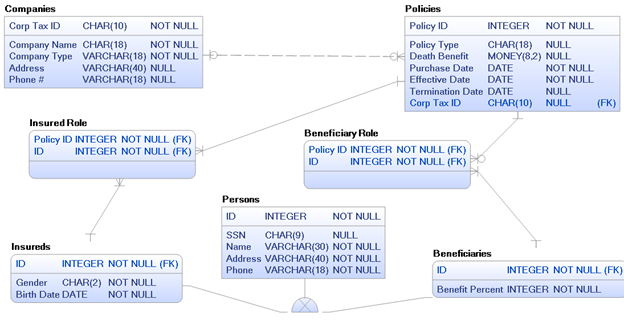
Figure 9: Better super-type is unique ID
Step #8: Construct of Role + Type = Power. Look back at Figure 9, the insured role and beneficiary role are only different by the type of person they relate to (i.e., different subtypes). Is there a viable way to combine these two bridging entities? Yes, we can model just one bridging or intersection entity with a relationship between person and policy with an added attribute of role type as shown below in Figure 10. This construct is one of the most powerful modeling techniques to add to your arsenal. This one tool can often reduce larger corporate models by dozens of entities when applied properly, plus the application logic required is not much more difficult for the programmers.
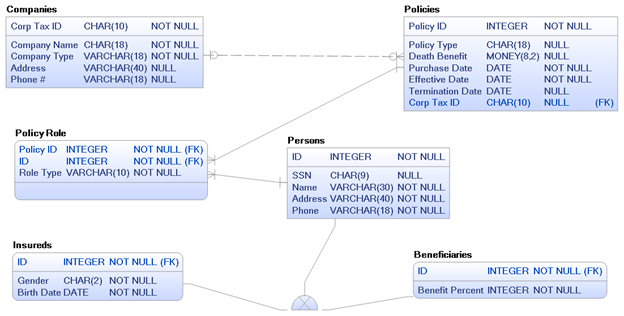
Figure 10: Use Role + Type
Step #9: Normalize the data model. Once you’ve got the business requirements generally right, now you can consider normalizing the model. And yes, I know, many people hate this step because it seems like some kind of useless academic exercise. However, it offers two extremely valuable business benefits: reducing data redundancy and improving data integrity. In short, it helps to keep the data effective, a highly desirable feature of any database.
Look at Figure 11 below which covers 1st through 3rd normal forms, the only ones that generally are targeted. The red arrows show the problem attribute and any dependencies they have to another attribute. Now, read those normal form descriptions while looking at these red arrows. It’s not very hard at all once you know the definition and have some rather simple visual examples.
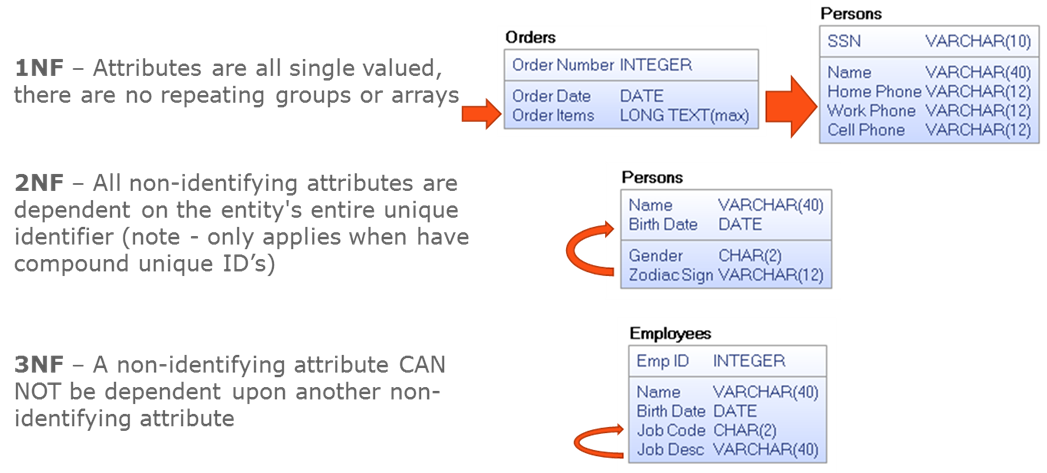
Figure 11: Data normalization
Step #10: Perform sanity checks before trying to implement your OLTP model. Data modeling tools like erwin Data Modeler offer many reports and utilities or tools for double checking your data models. These are all quick and easy to run, and very often find something of interest for further manual inspection. For example, maybe an attribute in one entity via a relationship to another entity somehow has a datatype mismatch, which can happen when you create attributes manually for relationships rather than letting the tool do it for you. Such a mistake is impossible to spot manually on anything but tiny models. So a report to look for that can find all such issues in the blink of an eye. The goal here is exception reporting – to only find the cases where a possible mistake occurred. If you’re lucky, this step won’t produce anything.
Conclusion
In this blog we examined the basic steps for OLTP data modeling, design and normalization for the cloud. The key issue to remember is that while the cloud is a great thing, a bad database design that requires either static overprovisioning or dynamic resources consumption can lead to high monthly expenses. And the best way to ensure good design is to follow advice like what I’ve offered above, while using a good data modeling tool like erwin Data Modeler.
Related links:
Like this blog? Watch the webinars: erwin Data Modeling 101-401 for the cloud
Case Study (Snowflake cloud): Credit Union Banks on erwin Data Modeler by Quest
Whitepaper: Meeting the Data-Related Challenges of Cloud Migration
Even more information about erwin Data Modeler
Video: Empower 2021: Fireside chat – Model-driven DevOps – What Is It?
Video: Empower 2021: Mitigating the risk associated with sensitive data across the enterprise
Webcast: Build better data models
Whitepaper: Top 10 Considerations for Choosing a Data Modeling Solution
Are you ready to try out the newest erwin Data Modeler?DevOps GitHub integration via MartOne-click push of data modeling data definition language (DDL) and requests to GitHub/Git repository via Mart. Get a free trial of erwin Data Modeler Got questions? Ask an Expert |
Join an erwin user group
Meet with fellow erwin users and learn how to use our solutions efficiently and strategically. To start, we’ll meet virtually twice a year, with plans to expand to meet in person. Hear about product roadmaps, new features/enhancements, interact with product experts, learn about customer successes and build and strengthen relationships. Join a group today.
Like this blog? Subscribe.
If you like this blog, subscribe. All you need to provide is your name and email located at the right margin of this blog post.
Help your colleagues
If you think your colleagues would benefit from this blog, share it now on social media with the buttons located at the right margin of this blog post. Thanks!
