Data Modeling 401 for the cloud: Database design for serverless data-bases in the cloud

*** This blog is based upon a recent webcast that can be watched here. ***
As with part 1, part 2 ,and part 3 of this data modeling blog series, this blog also stresses that the cloud is not nirvana. Yes, it offers essentially infinitely scalable resources. But you must pay for using them. When you make poor database design choices for applications deployed to the public cloud, then your company gets to pay every month for all those inherent, built-in inefficiencies. Static over-provisioning or dynamic scaling will run up monthly cloud costs very quickly due to that bad design, although capped at your cloud over sizing selection.
However, if you instead embrace newer serverless database options from vendors such as Snowflake and Amazon Redshift, then your database cloud resource usage becomes 100% dynamic (i.e. it auto-scales to maintain a service level agreement threshold). So, you pay for constant performance at the expense of uncapped monthly costs. In that scenario, bad database design can easily overwhelm any planned budget. So, for serverless databases, you really cannot afford to build in bad choices.

Serverless database deployment
First, let’s examine what a truly serverless database deployment option looks like. Below is a diagram showing an example for Amazon Redshift.
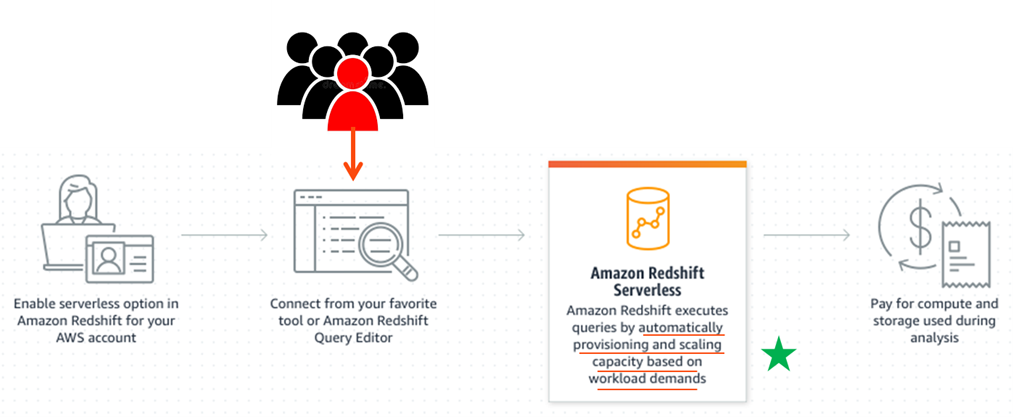
Figure 1: An example serverless database deployment in Amazon Redshift.
It’s actually a very simple option to deploy. But now the taxi meter runs non-stop at whatever rate is required to maintain the acceptable level of performance that you set. So, the database and its costs automatically scale up and down as needed. That can lead to some very high monthly charges if any of the following conditions hold true:
- More users than expected
- Users do more than expected
- User from hell does huge or inefficient things
- Database design does not scale well
Cloud database design choices
Now that we conceptually understand serverless databases, where do they fall into the cloud database design paradigm? Below is a diagram showing your choices under the Amazon AWS cloud.
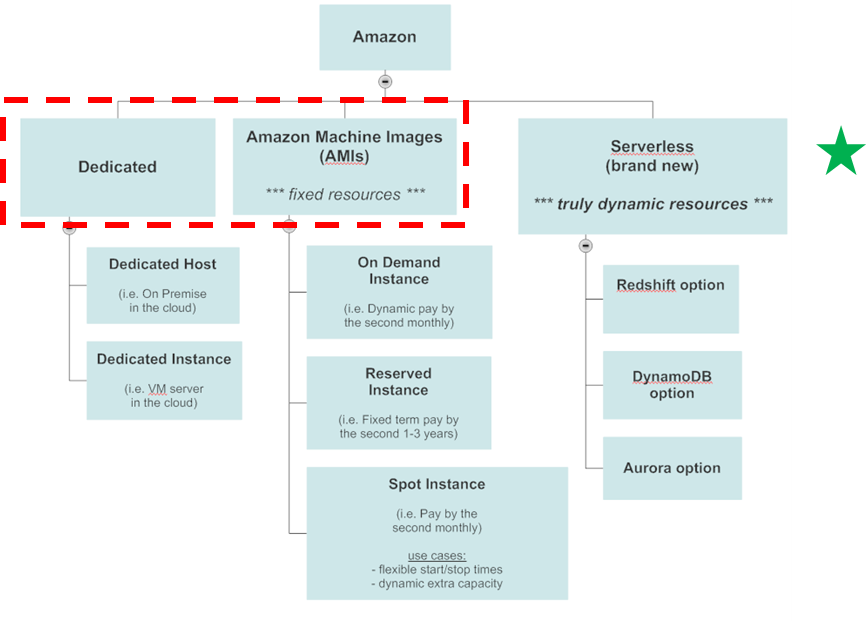
Figure 2: Serverless database options in Amazon AWS.
The first two choices encircled in red are the traditional fixed resource options: dedicated cloud servers vs. Amazon Machine images or AMI’s, which are essentially just virtual machines run on shared cloud servers. It’s the third leg, serverless, that is the new kid on the block. Now that cloud vendors such as Amazon are increasing their serverless database options by adding other databases such as DynamoDB and Aurora (e.g. MySQL and PostgreSQL), this trend is very likely to continue.
Here is a simple diagram showing what serverless databases are currently offered.

Figure 3: Serverless database offerings.
Data modeling best practices
Did you notice that the majority of these serverless databases are in fact just relational databases, a technology that we’re all quite accustomed to working with? So, good relational design as covered in part 1 of this data modeling blog series holds true. You should review both the data modeling 101 blog and webcast on relational databases. Below is an example of one such “best practice” for relational databases. Since logical data model many-to-many relationships cannot be physically implemented by a relational database, you must replace the many-to-many relationship with a bridging or intersection entity as shown below.
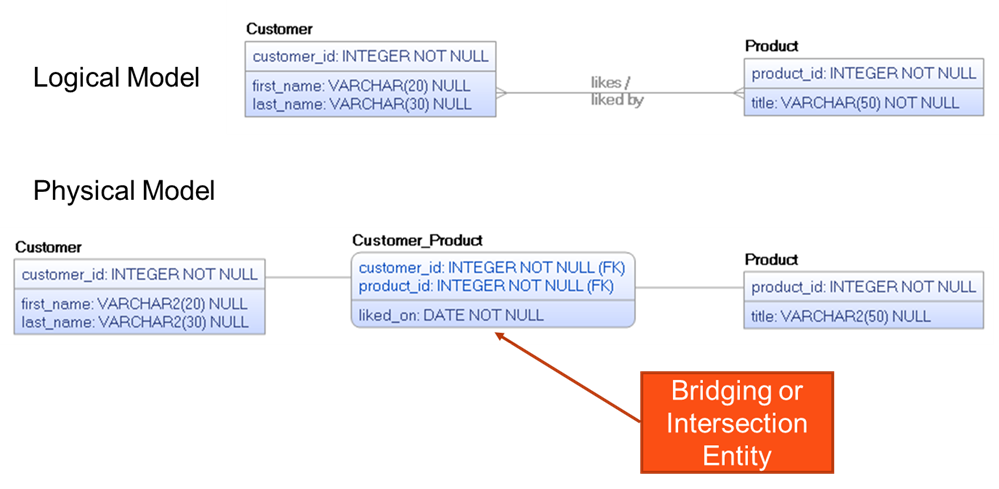
Figure 4: Replacing a many-to-many data model relationship with a bridging or intersection entity.
But what if you’re not creating a new database application, but rather converting an existing relational database to a serverless database such as Amazon Redshift. Are there data modeling tools to assist with such an effort? In fact, erwin offers multiple ways to accomplish this with great ease. Let’s say that you want to convert the existing Oracle data model to Redshift, you can simply choose to change the target database as shown below.
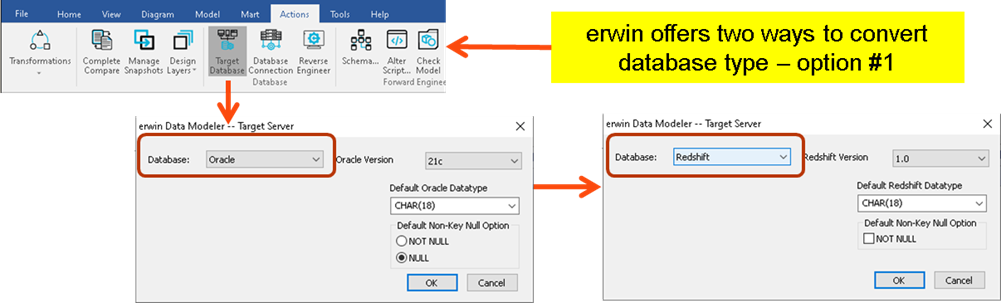
Figure 5: Converting an existing relational databases to a serverless database in erwin Data Modeler.
But of course, with this option you essentially lose your previously existing Oracle data model. What if you instead want to keep the old model and simply create a new data model that’s for Redshift? Well, erwin offers a simple way to do that instead as shown below (note that I chose Snowflake this time):
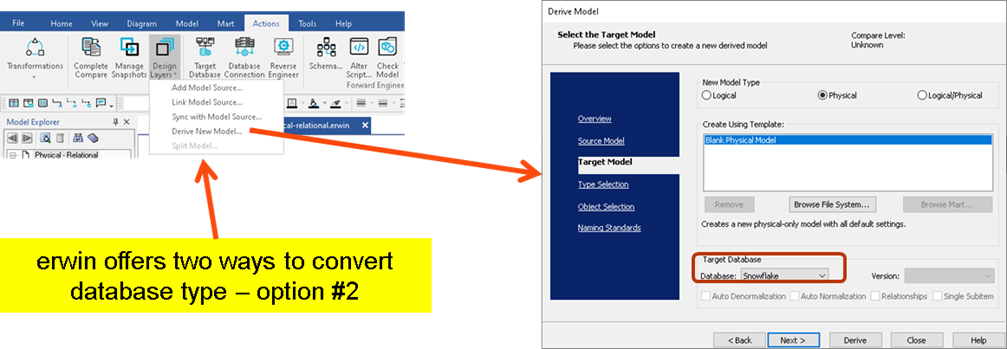
Figure 6: Creating a new data model for Redshift in erwin Data Modeler.
This method offers some very useful options for the conversion / transformation. Look just under the target selection circled in red, note the four check boxes currently disabled. Had I instead chosen a NoSQL database such as MongoDB or Cassandra, then those options would be enabled – and I would probably choose the “auto Denormalization” option. For a more through explanation and example of that, please refer back to review both the 201 blog and webcast on NoSQL databases.
Examples of bad database design choices
I want to wrap up this blog by giving you a very specific example of how a simple data modeling mistake can increase resource consumption and thus expenses of serverless databases. Imagine that you have a rather large data model with lots of entities and attributes. Further imagine that you also skip the model verification report before creating the database SQL from erwin. Imagine that if you manually create a relationship by adding the FK attributes directly rather than by graphically adding the relationship line, or maybe create the relationship line graphically but then make some manual changes to the FK attribute properties. Good data modeling tools like erwin will try to warn you not to do so and also offer model checking reports, but all tools allow you to override best practices since you know your data best. What would happen in this scenario? Well, any join between the parent and child tables would most likely not be able to leverage FK indexes due to the potential implicit data type conversions required. The end result is slow performance.
Not convinced? Here’s another example from a friends SQL Server database application being currently deployed. Half the application does not care about case sensitivity for auto make attributes (e.g. Honda, Toyota, etc.) while the other half requires it in all uppercase. There are legitimate scenarios where two tables can both need that attribute and it’s not a normalization issue. So, they must do a join using the uppercase function on both sides (to be safe), and yet they did not implement a function-based index on those attributes’ columns. So, the performance of the joins was horrible. Even after they later tested adding the function-based indexes, performance was still slower than acceptable. Further testing showed that the best solution was to standardize the attribute properties – but it was too late, the code was written and rolled out. So, now they get to pay for higher-than-normal cloud resource usage and it’s entirely due to bad database design. So again, the cloud is not Nirvana. And if using serverless databases, bad database design where the system just dynamically grows to compensate is a very expensive way to operate. Good database design for serverless databases is a true must. So, take the time to do it right and save your company lots of money (and possibly save your job as well).
Related links:
Like this blog? Watch the webinars: erwin Data Modeling 101-401 for the cloud
Blog: Data Modeling 101: OLTP data modeling, design, and normalization for the cloud
Blog: Data Modeling 201 for the cloud: designing databases for data warehouses
Case Study (Snowflake cloud): Credit Union Banks on erwin Data Modeler by Quest
Whitepaper: Meeting the Data-Related Challenges of Cloud Migration
Even more information about erwin Data Modeler:
Video: Empower 2021: Fireside chat – Model-driven DevOps – What Is It?
Video: Empower 2021: Mitigating the risk associated with sensitive data across the enterprise
Webcast: Build better data models
Whitepaper: Top 10 Considerations for Choosing a Data Modeling Solution
Are you ready to try out the newest erwin Data Modeler?DevOps GitHub integration via MartOne-click push of data modeling data definition language (DDL) and requests to GitHub/Git repository via Mart. Get a free trial of erwin Data Modeler Got questions? Ask an Expert |
Join an erwin user group.
Meet with fellow erwin users and learn how to use our solutions efficiently and strategically. To start, we’ll meet virtually twice a year, with plans to expand to meet in person. Hear about product roadmaps, new features/enhancements, interact with product experts, learn about customer successes and build and strengthen relationships. Join a group today.
Like this blog? Subscribe.
If you like this blog, subscribe. All you need to provide is your name and email located at the right margin of this blog post.
Help your colleagues
If you think your colleagues would benefit from this blog, share it now on social media with the buttons located at the right margin of this blog post. Thanks!
