Data Modeling 301 for the cloud: data lake and NoSQL data modeling and design

*** This blog is based upon a recent webcast that can be viewed here. ***
For NoSQL, data lakes, and data lake houses—data modeling of both structured and unstructured data is somewhat novel and thorny. This blog is an introduction to some advanced NoSQL and data lake database design techniques (while avoiding common pitfalls) is noteworthy. Moreover, this blog will provide readers with a firm foundation for NoSQL and data lakes as they move to the cloud.
As with the part 1 and part 2 of this data modeling blog series, the cloud is not nirvana. Yes, it offers essentially infinitely scalable resources. But you must pay for using them. When you make poor database design choices for applications deployed to the cloud, then your company gets to pay every month for all inevitably resulting inefficiencies. Static over-provisioning or dynamic scaling will run up monthly cloud costs very quickly on a bad design. So, you really should get familiar with your cloud provider’s sizing vs. cost calculator.
A sample data warehousing project
Look at Figure 1 below. I was pricing for a data warehousing project with just 4 TBs of data, small by today’s standards. I chose “ON Demand” for up to 64 virtual CPUs and 448 GB of memory since I wanted this data warehouse to fit entirely, or at least mostly, within memory. So that’s $136,000 per year to run just this one data warehouse in the cloud. If I can cut down on the CPU and memory needs, I can cut this cost significantly. So, I do not want to over-provision to be safe. I want to right size this from day one based upon a good database design that does not waste resources due to inefficient design.
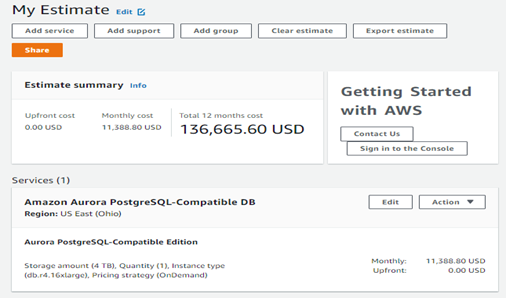
Figure 1: Pricing for a 4 TB data warehouse in AWS.
Data modeling basics
Now to cover some data modeling basics that apply whether your data is on-premises or in the cloud.
The first and most important thing to recognize and understand is the new and radically different target environment that you are most likely designing a data model when choosing a NoSQL database, namely a data lake or data lakehouse.
| OLTP | ODS | OLAP | DM/DW | Data Lake | |
| Business Focus | Operational | Operational Tactical | Tactical | Tactical Strategic | Analytical
Machine Learning |
| End User Tools | Client Server Web | Client Server
Web |
Client Server | Client Server
Web |
Cloud
Web |
| DB Technology | Relational | Relational | Cubic | Relational | Natural/Raw Format |
| Trans Count | Large | Medium | Small | Small | Varies |
| Trans Size | Small | Medium | Medium | Large | Varies |
| Trans Time | Short | Medium | Long | Long | Varies |
| Size in Gigs | 10 – 200 | 50 – 400 | 50 – 400 | 400 – 4,000 | 1,000 – 10,000 |
| Normalization | 3NF | 3NF | N/A | 0NF | N/A |
| Data Modeling | Traditional ER | Traditional ER | N/A | Dimensional | ??? |
Figure 2: Database design characteristics.
The data lake and data lakehouse are essentially high-powered analytical processing engines for vast amounts of both structured and unstructured data held within a database which can handle the data’s massive size and varying formats. Moreover, that database engine must be able to speedily process whatever queries are asked of it. Thus, many traditional relational databases like Oracle and Microsoft SQL Server may not be the best choice for such a highly specific and demanding need. This very specialized need gave rise to today’s many NoSQL databases.

But what exactly does NOSQL mean? The answer may surprise you. Look at this NoSQL definition from Wikipedia:
A NoSQL (originally referring to “non-SQL” or “non-relational”) database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases. Such databases have existed since the late 1960s, but the name “NoSQL” was only coined in the early 21st century (~1998), triggered by the needs of Web 2.0 companies. NoSQL databases are increasingly used in big data and real-time web applications. NoSQL systems are also sometimes called “Not only SQL” to emphasize that they may support SQL-like query languages or sit alongside SQL databases in polyglot-persistent architectures.
Note the four colorized sentences, especially the final one in red that’s also underlined. I’m willing to bet that at least two of those sentences were a surprise to you. But that’s all there is to a NoSQL database.
Here’s a diagram to explain the various NoSQL database types with example of such databases.
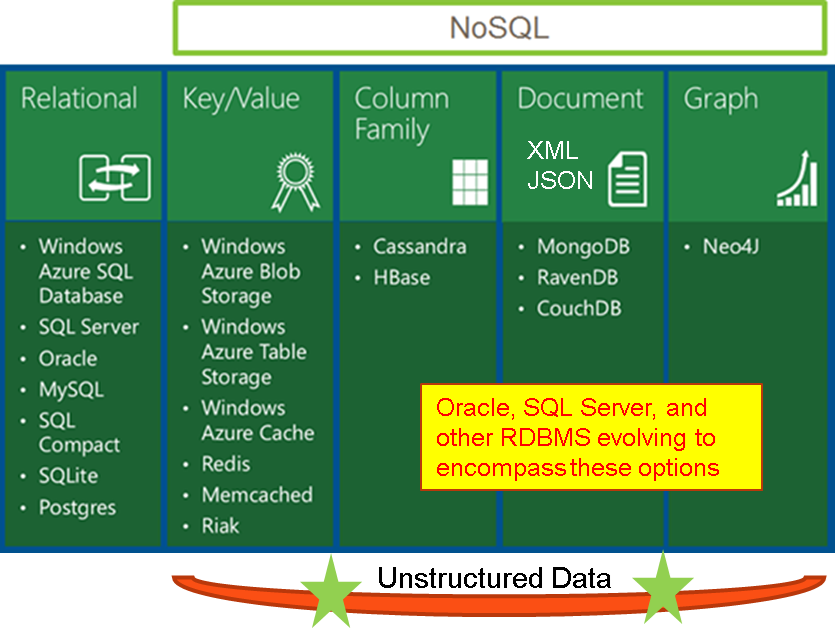
Figure 3: The types of NoSQL databases.
As the Wikipedia definition basically spelled out (the blue sentence), the key differentiator is that these databases store data in something other than tabular formatted tables. There are, however, three very common features among all the NoSQL databases:
- Cheap and easy, horizontal scale-out
- Flexible data structures (i.e. no schemas)
- Flexible data structures (i.e. no schemas)
I refer readers to this link regarding NoSQL databases which offers the diagram shown below to better explain what those three common features are.
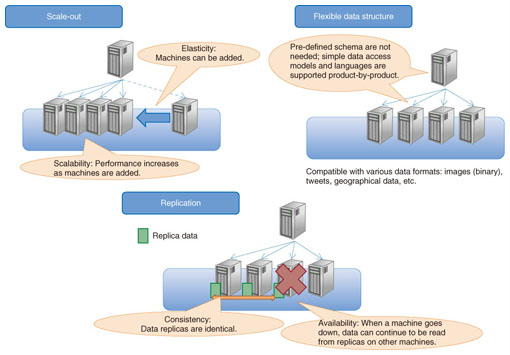
Figure 4: The three common features of NoSQL databases.
Now that we have a basic idea of what NoSQL means, why has it been so popular? The answer is the rapid explosion in the growth of data. Just to give you an idea of what these numbers really mean: if the earth were one gigabyte, then the sun would be an exabyte. So, the graph below says we need 50,000 suns for all of today’s data.
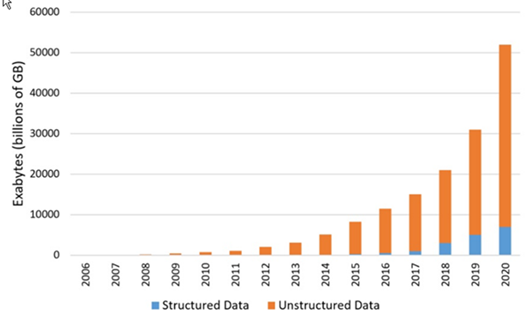
Figure 5: The staggering growth of unstructured data.
So, let’s now begin to data model NoSQL databases. For that, we must first embrace some important terminology differences. While you’re logically data modeling there really is no difference. However, once you begin physically data modeling some things are a wee bit different. But as long as your data modeling tool such as erwin handles those for you, it’s really no big deal.
| Modeling Concept | Relational | Column Oriented | Document |
| DBMS | Oracle | Cassanda | MongoDB |
| Owner | Schema | {Column Family} | —- |
| Entity | Table | Table | Collection |
| Attribute | Column | Column | Tag |
| Unique ID | Primary Key | Partition Key /
Clustering Key |
Collection Post |
| Relationship | Foreign Key | Collection | {References} |
Figure 6: Understanding the different modeling concepts.
So, now let’s create an example data model for a traditional relational database, then do the same exact thing for Cassandra and MongoDB. Nothing special here, just a typical logical many-to-many relationship solved via an intersection entity in the physical model.
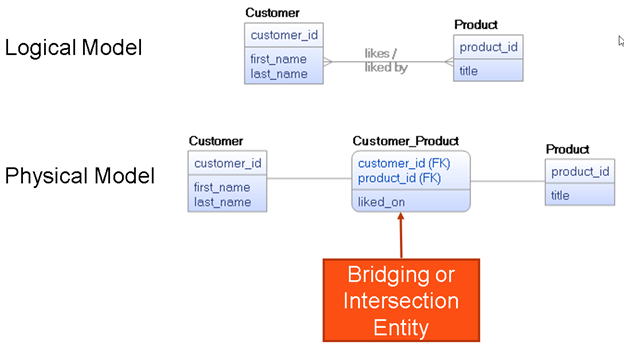
Figure 7: An example data model for a traditional relational database.
So, here’s the exact same physical data model done for Cassandra. Note that we now have four tables which are denormalized (as that’s the nature of the way things are done in NoSQL databases). Luckily the data modeling tool from erwin offers a utility to convert relational data models into NoSQL targets. So, even if you are new to NoSQL, erwin can help you with that initial effort until as such time as you begin to think and design properly in this new paradigm.

Figure 8: An example data model for a traditional relational database in Cassandra.
MondoDB is a little different as it offers two physical implementation options: embedded (figure 9) and normalized (figure 10) show here.
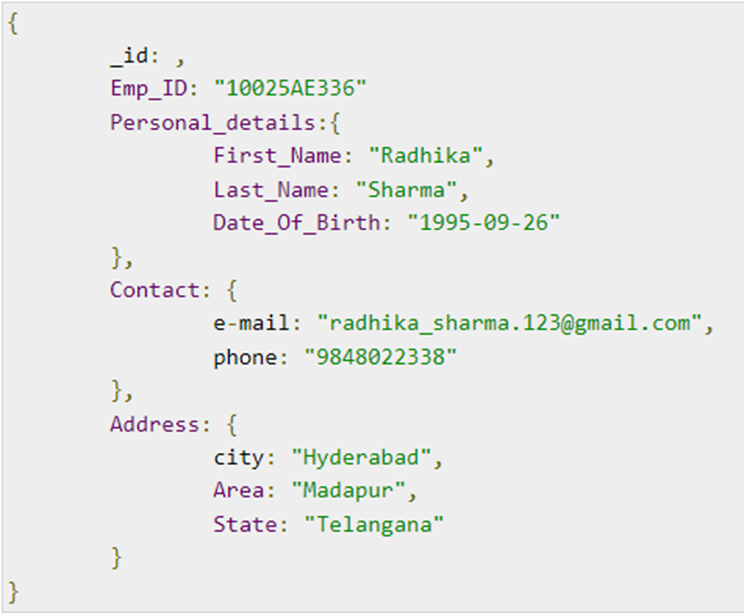
Figure 9: Embedded
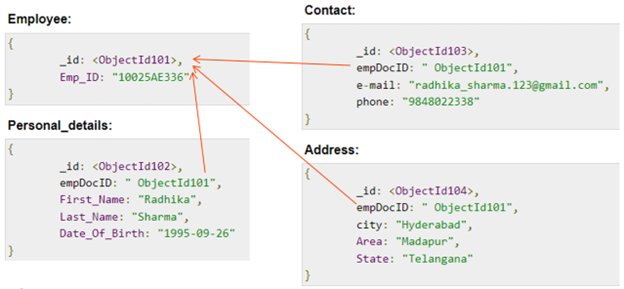
Figure 10: Normalized
My experience is that most people default to the embedded option and store their collections as XML or JSON objects. So, the erwin data model actually ends up looking exactly the same as the Cassandra data model.
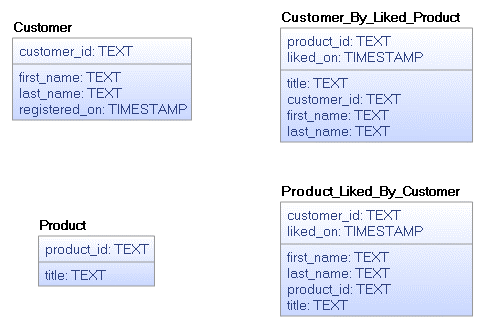
Figure 11: The erwin data model looks exactly the same as the Cassandra data model.
As we’ve seen in this blog, data modeling for a NoSQL database implementing a data lake is very different from doing one for an OLTP system. But there are techniques which can result in highly successful NoSQL data lake, and there are data modeling tools like erwin designed to support such data modeling efforts.
Related links:
Like this blog? Watch the webinars: erwin Data Modeling 101-401 for the cloud
Blog: Data Modeling 101: OLTP data modeling, design, and normalization for the cloud
Blog: Data Modeling 201 for the cloud: designing databases for data warehouses
Case Study (Snowflake cloud): Credit Union Banks on erwin Data Modeler by Quest
Whitepaper: Meeting the Data-Related Challenges of Cloud Migration
Even more information about erwin Data Modeler:
Video: Empower 2021: Fireside chat – Model-driven DevOps – What Is It?
Video: Empower 2021: Mitigating the risk associated with sensitive data across the enterprise
Webcast: Build better data models
Whitepaper: Top 10 Considerations for Choosing a Data Modeling Solution
Are you ready to try out the newest erwin Data Modeler?DevOps GitHub integration via MartOne-click push of data modeling data definition language (DDL) and requests to GitHub/Git repository via Mart. Get a free trial of erwin Data Modeler Got questions? Ask an Expert |
Join an erwin user group.
Meet with fellow erwin users and learn how to use our solutions efficiently and strategically. To start, we’ll meet virtually twice a year, with plans to expand to meet in person. Hear about product roadmaps, new features/enhancements, interact with product experts, learn about customer successes and build and strengthen relationships. Join a group today.
Like this blog? Subscribe.
If you like this blog, subscribe. All you need to provide is your name and email located at the right margin of this blog post.
Help your colleagues
If you think your colleagues would benefit from this blog, share it now on social media with the buttons located at the right margin of this blog post. Thanks!
